Epidemia - jak długo jeszcze?
Czyli co o epidemii może powiedzieć matematyk
Od ponad miesiąca żyjemy problemem epidemii w Polsce. Ministerstwo Zdrowia, drogą rozporządzeń, z butami weszło w nasze życie dyktując co wolno a co nie. Ale nie o tym dzisiaj - w końcu to polityka. Skoncentrujmy się na problemie: jak spróbować przewidzieć przyszłość?
Czy jest to w ogóle możliwe?

Narzędzia
Przewidywanie przyszłości jest domeną matematyki i fizyki. Fizyka eksperymentalna weryfikuje fizykę teoretyczną prowadząc doświadczenia, które potwierdzają lub obalają teorię. Spróbujmy i my dzisiaj zastosować podobne metody w nieco prostszym przypadku: jak przewidzieć ilość zarażonych ludzi w kolejnych dniach epidemii. Do tego celu będziemy potrzebowali dość prostego, acz potężnego mechanizmu, który w dodatku sami spróbujemy stworzyć. Załóżmy, że będzie to funkcja, której argumentem będzie numer dnia liczony od ustalonej przez nas daty, a wartością - liczba osób zakażonych. Moglibyśmy zatem taką funkcję zapisać następująco:
$$ f(x): \mathbb{N} \ni x \to f(x) \in \mathbb{N} $$
Tłumacząc na język polski: chcemy stworzyć funkcję, która przyjmie jeden argument - liczbę naturalną oraz zwróci wynik - także jedną liczbę naturalną. Umówmy się też, co dla nas oznaczać będzie \(x = 0\): to dzień, w którym zdiagnozowano pierwszy przypadek koronawirusa w Polsce - 4 marca 2020. Dla uproszczenia obliczeń będziemy się tutaj posługiwali ilością dni, które upłynęły od tej daty, a nie datami z kalendarza. Tak więc: \(x=1\) to 5 marca, \(x=2\) - 6 marca itd. Wynik tej funkcji będziemy interpretowali dosłownie jako liczbę zarażonych osób. Większość krzywych, którymi będziemy starali się przybliżać funkcję f będzie jednak ciągła - tzn. będzie zwracała liczby rzeczywiste. Ponieważ ciężko nam wyrazić liczbę osób inaczej niż liczba naturalna (ile to dokładnie jest π osób? albo 3/4 osoby?) możemy przyjąć, że za ilość osób zarażonych umownie przyjmiemy najbliższą liczbę naturalną nie większą niż zwrócona liczba rzeczywista.
Strzałka czasu
Przeszłość od przyszłości różni się w dość ciekawy sposób: przeszłość znamy doskonale, o przyszłości jednak nie mamy bladego pojęcia. Posiadamy wspomnienia z przeszłości, ale nie z przyszłości. Co gorsze, mając nawet wróżbę lub przewidywanie dotyczącą przyszłości na dzień dzisiejszy nie potrafimy ich w żaden sposób zweryfikować. Jedyne, co możemy, to obejrzeć się w przeszłość i ocenić jak dobrze dane przewidywanie pokrywa się z danymi historycznymi licząc na to, że w przyszłości będzie podobnie. Możemy też modyfikować nasze przewidywanie w miarę otrzymywania danych w kolejnych dniach. Dzisiaj wiemy już jak przebiegała epidemia w poprzednich dniach. Tabelka poniżej stanowi zapis historii:
| Dzień epidemii – x | Ilość zarażeń – y | Dzień epidemii – x | ilość zarażeń – y |
|---|---|---|---|
| 0 | 1 | 18 | 634 |
| 1 | 1 | 19 | 749 |
| 2 | 5 | 20 | 901 |
| 3 | 6 | 21 | 1051 |
| 4 | 11 | 22 | 1221 |
| 5 | 17 | 23 | 1389 |
| 6 | 22 | 24 | 1638 |
| 7 | 31 | 25 | 1862 |
| 8 | 51 | 26 | 2055 |
| 9 | 68 | 27 | 2311 |
| 10 | 104 | 28 | 2554 |
| 11 | 125 | 29 | 2946 |
| 12 | 177 | 30 | 3383 |
| 13 | 238 | 31 | 3627 |
| 14 | 287 | 32 | 4102 |
| 15 | 355 | 33 | 4413 |
| 16 | 425 | 34 | 4848 |
| 17 | 536 | 35 | 5205 |
To są dane na dzień dzisiejszy historyczne, pochodzą one ze strony epidemia-koronawirus.pl. Skoro są to dane historyczne, to chcielibyśmy, aby nasze przewidywanie przyszłości – funkcja \(f\) – potrafiło także "cofnąć" się w przeszłość i podać wyniki mniej więcej zgodne z tymi, które zostały oficjalnie podane. Zatem jednym z ważnych kryteriów funkcji, która ma za zadanie przewidzieć przyszłość będzie także test na danych historycznych. Spróbujemy zatem w jakiś sposób oszacować jak bardzo poprawnie nasza funkcja odtwarza przeszłość rozwoju epidemii. Do tego celu będzie nam potrzebne dodatkowe narzędzie: oszacowanie błędu.
Oszacowanie błędu
Jak możemy porównać wyniki funkcji \(f\) i danych z tabelki powyżej? Najprościej - moglibyśmy odjąć wartości podane przez naszą "proroczą" funkcję od wartości aktualnych a następnie zsumować. Wyglądałoby to mniej więcej tak:
$$ E = f(x_0) - y_0 + f(x_1) - y_1 + \cdots + f(x_n) - y_n $$
Gdzie \(x_i\) oraz \(y_i\) to po prostu wartości wzięte z tabeli powyżej odpowiadające \(i\)-temu dniu epidemii. Problem polegałby jednak na tym, że jeśli raz funkcja zwróciłaby wartość o 1 większą a raz o 1 mniejszą od wartości oczekiwanych, to tak zdefiniowany błąd byłby równy 0. A przecież funkcja pomyliła się i to aż dwa razy! Poprawmy zatem naszą procedurę: dodajmy wartość bezwzględną, która umożliwi nam zwracanie zawsze dodatnich wartości jednostkowych błędu:
$$ E = |f(x_0) - y_0| + |f(x_1) - y_1| + \cdots + |f(x_n) - y_n| $$
Po zsumowaniu powyższy przykład zwróci 2 - dokładnie tak, jak się spodziewaliśmy. Dodatkowo udało nam się otrzymać jeszcze jeden wielki bonus - jeśli błąd jest równy 0, to wiemy, że funkcja perfekcyjnie odtworzyła historię!
Tak zdefiniowana funkcja błędu ma ciekawe własności:
- jest zawsze nieujemna, tj. \(E ≥ 0\),
- gdy dane historyczne dokładnie pokrywają się z wartościami zwróconymi przez funkcję \(f\), to błąd równa się 0,
Pierwsza własność wynika bezpośrednio z faktu, że sumujemy nieujemne wartości. Czytelnikowi pozostawiamy dowód tego twierdzenia do przeprowadzenia w domowym zaciszu. Druga własność to szczególny przypadek, gdzie każda wartość oczekiwana zgadza się z wartością zwróconą przez funkcję \(f\) - wtedy sumujemy same zera i w efekcie dostajemy zero.
Możemy wyobrazić sobie więcej oszacowań błędu mających podobne właściwości. Na przykład: moglibyśmy zastąpić z powodzeniem wartość bezwzględną kwadratem różnicy i otrzymalibyśmy równie użyteczne przybliżenie błędu. Mówimy o czymś takim:
$$ E = (f(x_0) - y_0)^2 + (f(x_1) - y_1)^2 + \cdots + (f(x_n) - y_n)^2 $$
W dodatku moglibyśmy jeszcze sumę końcową obłożyć pierwiastkiem. Otrzymalibyśmy wtedy dokładnie normę euklidesową - w szkole tym sposobem obliczaliśmy odległość między dwoma punktami na płaszczyźnie.
Oczywiście moglibyśmy używać jeszcze wyższych potęg – wtedy otrzymalibyśmy ogólny wzór na normę w przestrzeni Lp, ale nie na to chciałbym zwrócić uwagę. Pierwsza z metod oszacowania błędu - ta z wartością bezwzględną - ma jedną bardzo poważną wadę. Otóż nie jest różniczkowalna. Czy w ogóle powinniśmy się tym przejmować? Tak, o ile zależy nam na minimalizacji tego błędu! Oszacowanie błędu, które samo w sobie nie jest rózniczkowalne, jest kłopotliwe w użyciu, gdyż utrudnia znalezienie minimum. Natomiast druga z opisywanych metod jest różniczkowalna w całej swojej dziedzinie, co pozwala na użycie pochodnych, do odnalezienia kierunku, w którym oszacowanie błędu maleje o ile tylko sama funkcja \(f\) także jest różniczkowalna. Pochodna takiej funkcji będzie zatem drogowskazem - w którą stronę regulować potencjalne parametry naszej funkcji \(f\) tak, aby zbliżała się wartościami do danych, które już zebraliśmy. Czyżby nam już coś świtało? Tak - w matematyce istnieje metoda najmniejszych kwadratów, która pozwala na dopasowanie zadanej funkcji do danych, które już zebraliśmy. Wprowadźmy dodatkową funkcję: funkcję błędu, która będzie nas informowała jak "daleko" nasza funkcja \(f\) odbiega od danych historycznych. Jej wzór jest poniżej:
$$ E(f, x, y) = \sqrt{\sum\limits_{i=0}^{n} (f(x_i) - y_i)^2}$$
Skąd wziąć \(n\)? To proste - to przecież ilość dni, która trwa już epidemia - aż do dnia wczorajszego. \(x_i\) - to po prostu kolejne dni epidemii licząc od zera. Moglibyśmy tutaj użyć też po prostu \(i\), ale założyłem możliwość, że z któregoś dnia możemy nie mieć danych - cóż, zdarza się i tak. Teraz to nie problem, ale kto wie, co będzie w przyszłości. \(y_i\) - liczba chorych w \(i\)-tym dniu. Prawa kolumna z tabelki powyżej. Gotowi? No to idziemy dalej!
Wyrzeźbmy sobie funkcję
W naszym narzędziowniku mamy już zatem: pomysł jak w języku matematyki wyrazić postęp epidemii - będzie to funkcja, która jako argument pobierze numer dnia epidemii licząc od zera oraz zwróci liczbę zarażonych. Wiemy, że dobrym pomysłem jest porównanie wartości już zebranych i wykorzystanie ich do tego, aby spróbować naszą funkcję "dostroić". Mamy w końcu też dobry pomysł na oszacowanie błędu, a także - gotową metodę, która powinna nam umożliwić bezpośrednio "strojenie" parametrów naszej funkcji. Jesteśmy zatem gotowi, aby zabrać się za epidemię narzędziami matematykI! Dodatkowo spróbujmy wykorzystać komputer jako narzędzie, które pomoże nam z czasami trudnymi, a z pewnością mozolnymi obliczeniami. W artykule zamieszczę wyłącznie wzory i wykresy, kod źródłowy wraz z danymi udostępnione zostaną jako materiały do pobrania na dole strony.
Może spróbujemy funkcji afinicznej?
$$ f(x) = ax + b $$
Mamy tutaj tylko dwa parametry: \(a\) i \(b\). Parametr \(a\) oznacza nachylenie prostej, zaś \(b\) powoduje przesunięcie prostej względem osi OY (lub - jeśli ktoś woli - "w górę" lub "w dół"). Użycie tej funkcji daje jednak dość przykre efekty: 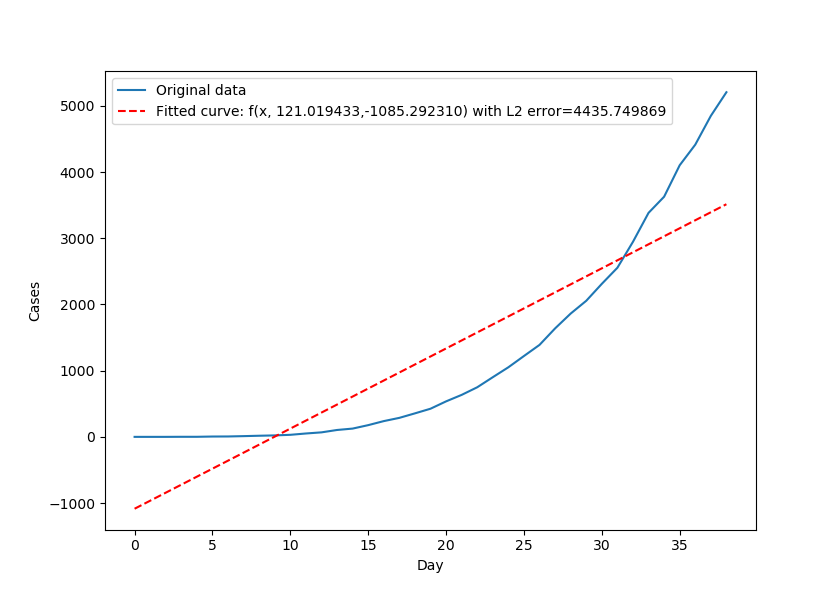 Funkcja widocznie "rozmija" się z danymi. W dodatku funkcja afiniczna nie będzie potrafiła przybliżyć końca epidemii - przecież ona rośnie (lub maleje) w kierunku nieskończoności! Czyżbyśmy zrobili jakiś błąd? Zasadniczo tak - użyliśmy być może niewłaściwej funkcji. Spróbujmy zatem czegoś innego.
Funkcja widocznie "rozmija" się z danymi. W dodatku funkcja afiniczna nie będzie potrafiła przybliżyć końca epidemii - przecież ona rośnie (lub maleje) w kierunku nieskończoności! Czyżbyśmy zrobili jakiś błąd? Zasadniczo tak - użyliśmy być może niewłaściwej funkcji. Spróbujmy zatem czegoś innego.
Czas na funkcję wykładniczą!
$$ f(x) = a^x $$
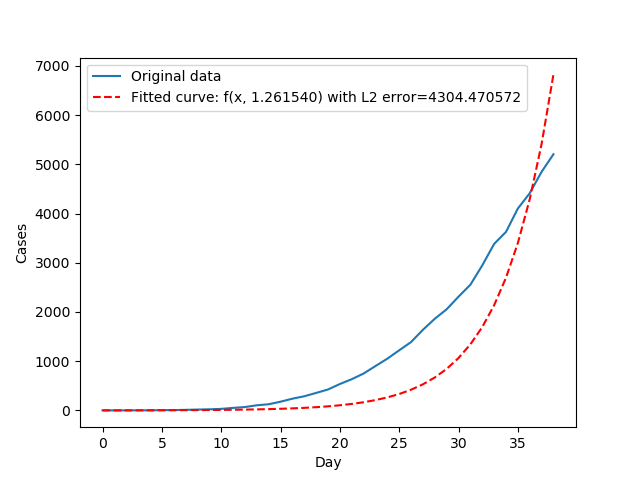 Tutaj znów pojawia się pewien problem. Co prawda dopasowanie danych odrobinę się poprawiło, ale nadal jest źle. Funkcja, która nie potrafi nawet dobrze przybliżać danych historycznych nie będzie z pewnością dobrym kandydatem do wróżenia nt. przyszłości. Zauważmy, że we wzorze mamy tylko jeden parametr - podstawę \(a\). Spróbujmy dodać odrobinę dodatkowych parametrów i zobaczymy, co z tego wyniknie. Być może uda się nieco zmienić nachylenie krzywej.
Tutaj znów pojawia się pewien problem. Co prawda dopasowanie danych odrobinę się poprawiło, ale nadal jest źle. Funkcja, która nie potrafi nawet dobrze przybliżać danych historycznych nie będzie z pewnością dobrym kandydatem do wróżenia nt. przyszłości. Zauważmy, że we wzorze mamy tylko jeden parametr - podstawę \(a\). Spróbujmy dodać odrobinę dodatkowych parametrów i zobaczymy, co z tego wyniknie. Być może uda się nieco zmienić nachylenie krzywej.
Funkcja potęgowa
$$ f(x) = a\cdot b^x $$
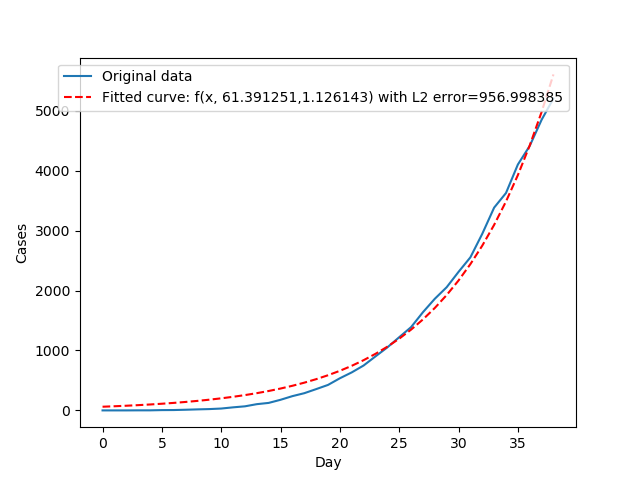 Widać znaczną poprawę. Po raz pierwszy trafiamy w dane i ustalamy trend wzrostu. Informacja, którą przynosi nam ta funkcja jest niestety przykra: wzrost wykładniczy oznacza, że liczba chorych bardzo szybko będzie rosnąć. Problemem z predykcją przy użyciu funkcji wykładniczej jest także fakt, że populacja ludzka jest skończona, zaś sama funkcja wykładnicza rośnie w nieskończoność. Czy istnieje jakaś metoda przybliżenia rozrostu epidemii, która bierze pod uwagę ograniczenia liczby ludzi oraz samego wzrostu epidemii?
Widać znaczną poprawę. Po raz pierwszy trafiamy w dane i ustalamy trend wzrostu. Informacja, którą przynosi nam ta funkcja jest niestety przykra: wzrost wykładniczy oznacza, że liczba chorych bardzo szybko będzie rosnąć. Problemem z predykcją przy użyciu funkcji wykładniczej jest także fakt, że populacja ludzka jest skończona, zaś sama funkcja wykładnicza rośnie w nieskończoność. Czy istnieje jakaś metoda przybliżenia rozrostu epidemii, która bierze pod uwagę ograniczenia liczby ludzi oraz samego wzrostu epidemii?
Model wzrostu epidemii Jamesa Hollanda Jonesa
Powstały na uniwersytecie Harvarda model jest zawiły dla początkującego czytelnika. Oto i wzór:
$$ f(x) = \frac{1}{1+\frac{1-a}{a}e^{-bx}}$$
Widzimy tutaj znowu dwa parametry: \(a\) oznaczający ułamek populacji początkowo zarażonej przez wirusa. Raczej będzie to bardzo mała liczba. Parametr \(b\) oznaczający szybkość rozprzestrzeniania się wirusa. Jest to analogia do "zaraźliwości" wirusa. Im większy, tym gorzej dla nas. Funkcja przyjmuje wartości z przedziału: \([0, 1]\) więc dla potrzeb naszej symulacji wymnożymy ją jeszcze przez dodatkowy parametr \(c\) oznaczający maksymalny rozmiar epidemii. Finalnie nasz wzór będzie wyglądał następująco:
$$ f(x) = \frac{c}{1+\frac{1-a}{a}e^{-bx}} $$
Parametr \(c\) należy utożsamiać z rozmiarem populacji. Jeśli bierzemy pod uwagę Polskę, to parametr \(c\) mógłby wynosić nawet ok. 37.97 miliona. Miejmy jednak nadzieję, że epidemia nie rozrośnie się do takich rozmiarów. Spróbujmy zatem dopasować funkcję do danych zebranych do tej pory i przewidzieć dalsze rozprzestrzenianie się wirusa.
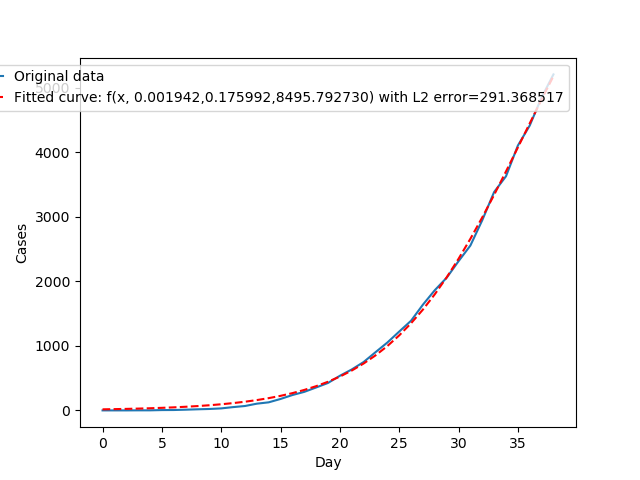
Jak widzimy, dopasowanie do danych historycznych jest niemal idealne. Zauważmy też, że parametr \(c\) wynosi niespełna 8500, co zarazem wyznacza górną liczbę zachorowań. Wykreślmy jeszcze za pomocą tego modelu prognozę na następne dni. Zwróćmy uwagę, że wykres zaczyna się nadal w dniu 0 - czyli 4 marca.
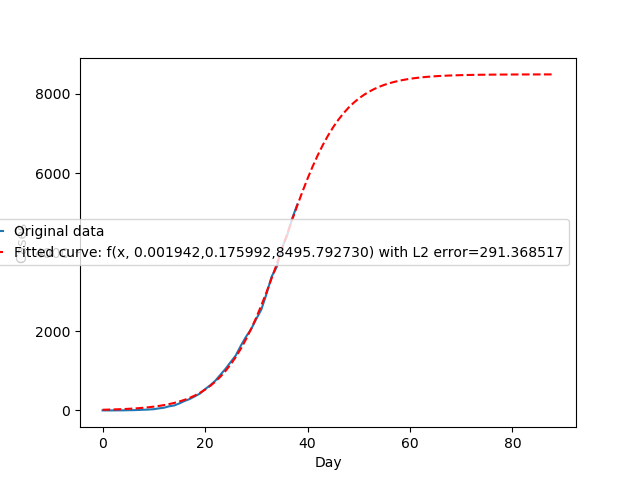
Przy założeniu tego modelu faktycznie maksymalna liczba zarażonych osób to ok. 8500, a maksimum to zostanie osiągnięte za ok. dwa tygodnie. To niewiele, jednak aby całkowicie wyhamować epidemię musimy odczekać jeszcze ok. miesiąca aż wszystkie zarażone osoby przestaną zarażać innych. Wtedy też będzie można oficjalnie zdjąć restrykcjei powrócić pomału do normalnego życia.
Inne symulacje
Twórca kanału 3Blue1Brown na portalu Youtube przeprowadził znacznie bardziej skomplikowane symulacje, które zarazem mają znacznie bardziej atrakcyjną formę od prostego dopasowania wykresu. Film poniżej - polecam!
Co z tego wynika?
Tworząc powyższe modele przyjęliśmy dość trudne do spełnienia w praktyce założenia:
- Model opisuje faktyczną sytuację i bierze pod uwagę wszystkie możliwe czynniki.
- Środowisko nie ma ograniczeń typu budynki, izolujące się jednostki, duży dystans między poszczególnymi osobami.
- Wybrane równania mają jakiekolwiek sprawdzone podstawy teoretyczne.
I tutaj czeka nas klops: niestety nie ma uniwersalnego prawa, podobnego do praw fizyki, które działałoby zawsze i w każdym miejscu. Cytowany już wcześniej eksperyment z uniwersytetu Stanforda stworzył raczej intuicyjne oszacowania niż udowodnione twierdzenia. Przykładowe ograniczenie z punktu 2 wyraża się tylko za pomocą jednego parametru. To niestety mocno ogranicza sprawdzalność prognoz.
Starajmy się maksymalnie izolować, gdyż izolacja w równaniu modelu z uniwersytetu Stanforda zmniejsza parametr \(b\), a co za tym idzie - ogranicza rozprzestrzenianie się wirusa. Starając się unikać kontaktów z innymi ludźmi możemy dość szybko wstrzymać epidemię, podobnie jak stało się to w Korei Południowej. Musimy jednak sami decydować o tym każdego dnia trwania epidemii.
Żaden obecnie istniejący model nie potrafi dokładnie przewidzieć przyszłości, gdyż w znacznym stopniu zależy ona od zachowań ludzi, którzy w przeciwieństwie do większości obiektów w fizyce są bardzo mało przewidywalni.
Zdrowia dla wszystkich!
Konrad Sewiłło-Jopek
Referencje
- Optymalizacja dopasowania krzywych
- Model opracowany na uniwersytecie Harvard
- Metoda najmniejszych kwadratów - Uniwersytet Wrocławski